从RLHF、PPO到GRPO再训练推理模型,这是你需要的强化学习入门指南
从RLHF、PPO到GRPO再训练推理模型,这是你需要的强化学习入门指南强化学习(RL)已经成为当今 LLM 不可或缺的技术之一。从大模型对齐到推理模型训练再到如今的智能体强化学习(Agentic RL),你几乎能在当今 AI 领域的每个领域看到强化学习的身影。
来自主题: AI技术研报
8835 点击 2025-06-22 16:08
 搜索
搜索
强化学习(RL)已经成为当今 LLM 不可或缺的技术之一。从大模型对齐到推理模型训练再到如今的智能体强化学习(Agentic RL),你几乎能在当今 AI 领域的每个领域看到强化学习的身影。
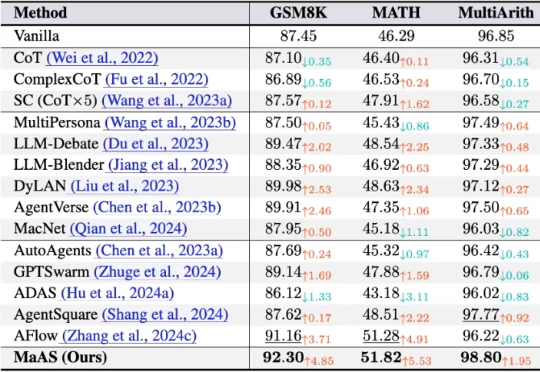
LLM 智能体的时代,单个 Agent 的能力已到瓶颈,组建像 “智能体天团” 一样的多智能体系统已经见证了广泛的成功
LLM 和 agent 最关键的能力之一就是基于 context 来准确完成用户的任务,而最真实、鲜活的 context 往往不在 Google doc 等文档中,而是存在人与人的对话中,纪要就承载着这一类高价值信息。

近年来,大型语言模型(LLM)在处理复杂任务方面取得了显著进展,尤其体现在多步推理、工具调用以及多智能体协作等高级应用中。这些能力的提升,往往依赖于模型内部一系列复杂的「思考」过程或 Agentic System 中的 Agent 间频繁信息交互。
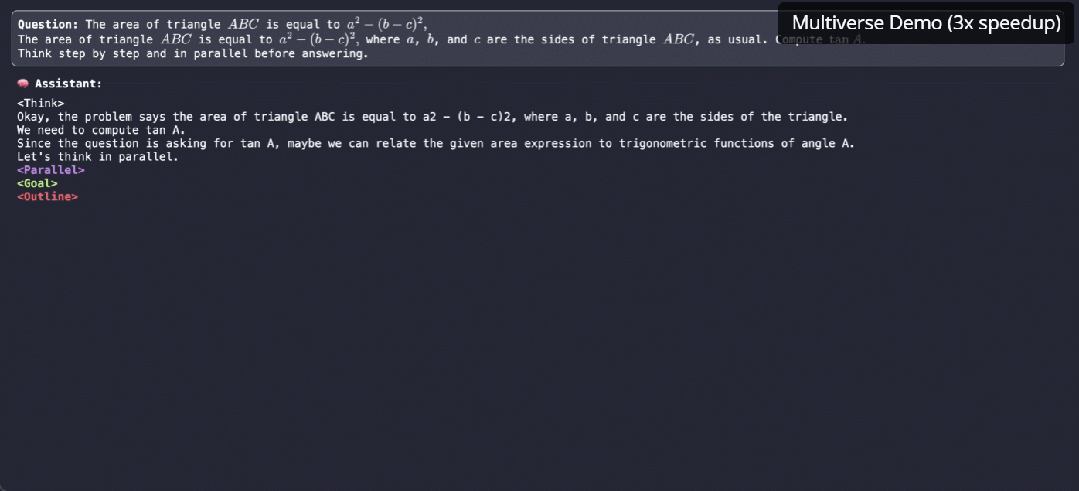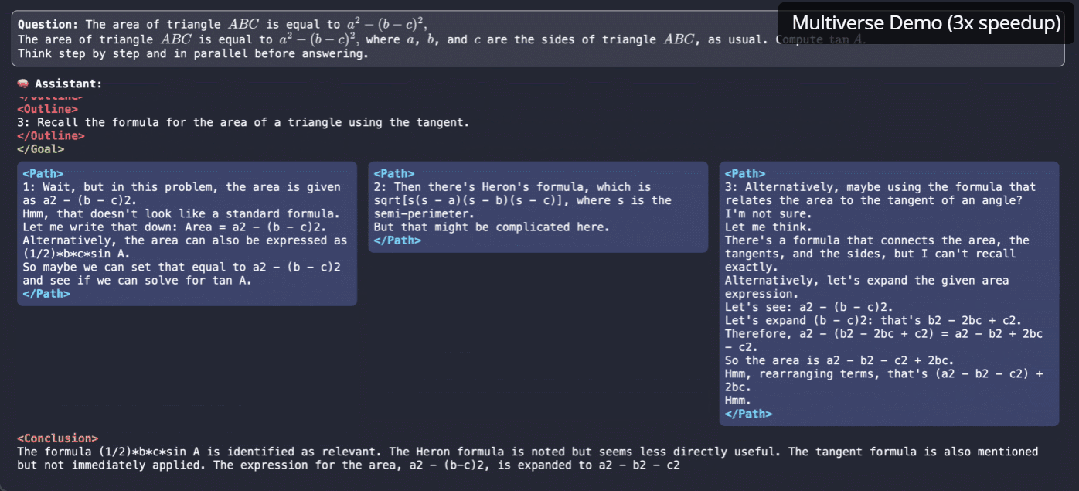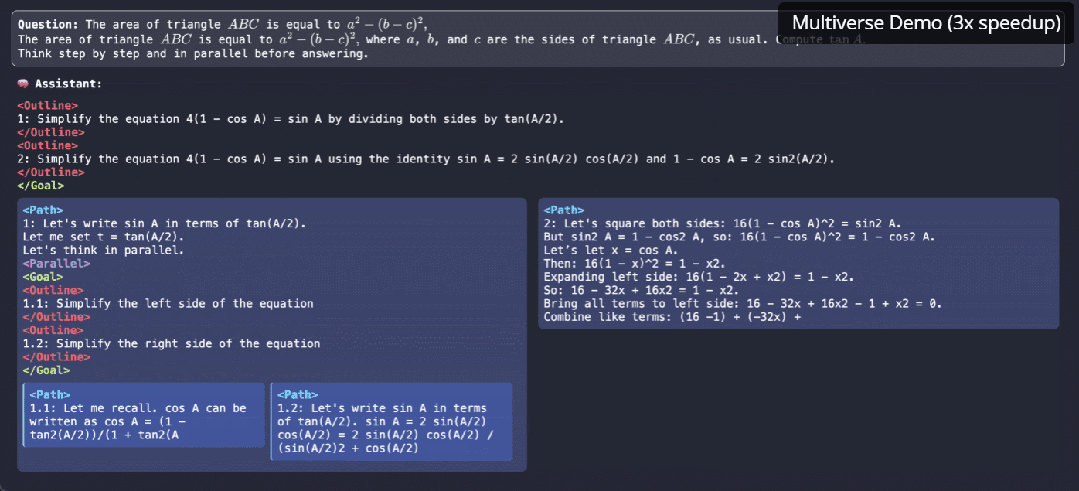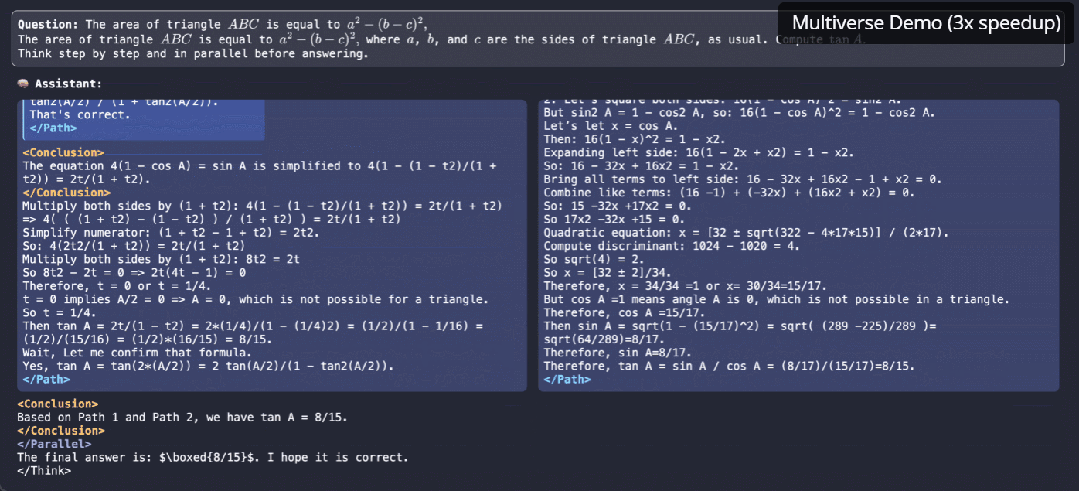
原生并行生成不仅仅是加速,它是我们对 LLM 推理思考方式的根本转变。
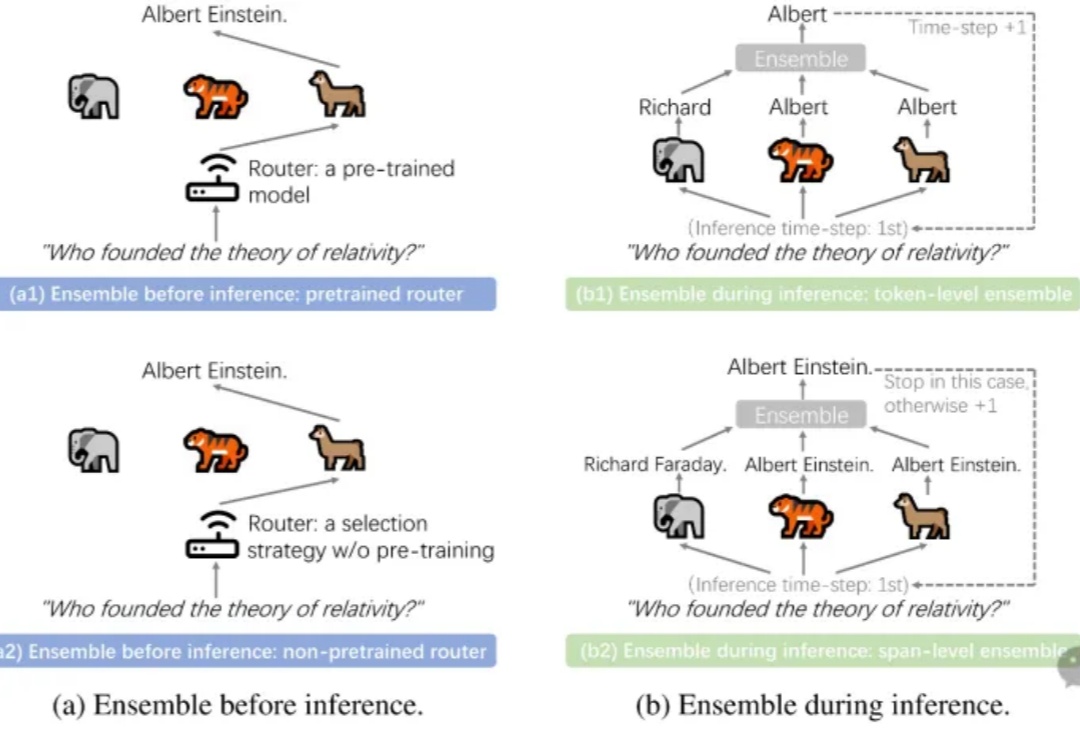
LLM Ensemble(大语言模型集成)在近年来快速地获得了广泛关注。它指的是在下游任务推理阶段,综合考虑并利用多个大语言模型(每个模型都旨在处理用户查询),从而发挥它们各自的优势。大语言模型的广泛可得性,以及其开箱即用的特性和各个模型所具备的不同优势,极大地推动了 LLM Ensemble 领域的发展。

本文深入剖析 MiniCPM4 采用的稀疏注意力结构 InfLLM v2。作为新一代基于 Transformer 架构的语言模型,MiniCPM4 在处理长序列时展现出令人瞩目的效率提升。传统Transformer的稠密注意力机制在面对长上下文时面临着计算开销迅速上升的趋势,这在实际应用中造成了难以逾越的性能瓶颈。

您可能会问,LLM Agent的SOP到底是什么,为什么称它为AI的高考?SOP全称是标准操作程序(Standard Operating Procedures)很多朋友可能很熟悉,但它绝不是简单的步骤清单——它更像是AI能否在工业环境中真正"上岗"的终极考验。

当前,强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。DeepSeek R1、Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。

World Labs 是由著名 AI 专家、斯坦福大学教授李飞飞于 2024 年创办的初创公司,致力于开发具备“空间智能”的下一代 AI 系统。